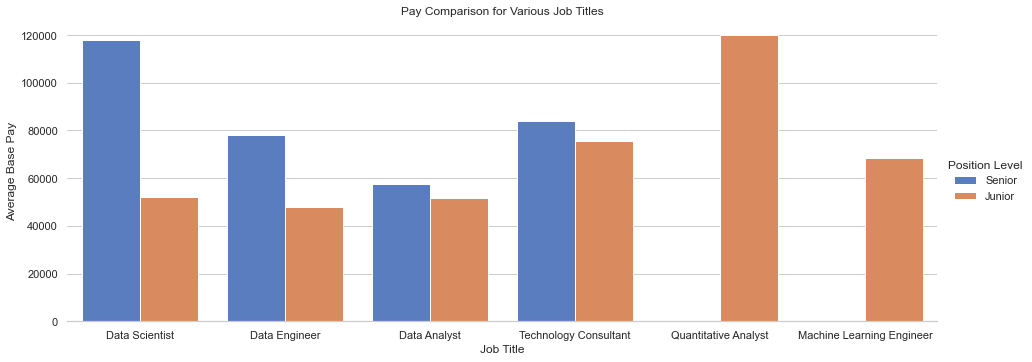
Personal Project - As graduation approaches, I decided that it would be beneficial to get an overview of the Data centred jobs in Singapore. Therefore, I decided to scrap the popular job site, Glassdoor, to gather data on the jobs on the market and have the bigger picture of the job market.
Methodology
-
- Usage
-
- Data Collection Approach
-
- Findings
- 3.1 Number of Job Listings per Job Title
- 3.2 Minimum Education Level Required
- 3.3 Technical Skills Requested for Jobs
- 3.4 Academic Skills Requested for Jobs
- 3.5 Hires by ownership type
- 3.6 Job Description Word Cloud
-
- Conclusions
-
- Acknowledgement
-
- Files in this Repository
-
- Disclaimer
1. Usage
The project is written in a Jupyter Notebook file with the Python Language. For easy viewing of the project sections, I have included a viewer website that contains these Jupyter Notebook. I have split the notebooks into the various overarching task I performed for this project.
2. Data Collection Approach
I chose Glassdoor as the website to attain my data due to the depth and breadth of companies posted. I intended to collect data from Linkedin Jobs as well but due to obfuscation, I had difficulty attaining the data.
Unfortunately, Glassdoor do not have any public API available, therefore I utilised a web scraper to collect the information on the postings on the site.
I utilised selenium package within Python to scrap the website as Glassdoor renders it webpage with Javascript instead of HTML, therefore, we needed the user input function selenium has to offer. The data was pulled on the 22nd May 2020.
3. Findings
The subsections below contains my key findings, where the source code can be found in Section 1.
3.1 Number of Job Listings per Job Title
I wanted to find out the job demand through using the metrics of job numbers. We found that the highest job listings was for Data Scientist.
| Job Title | Number of Jobs | Relative Frequency, % |
|---|---|---|
| Data Scientist | 925 | 45.00 |
| Data Analyst | 477 | 23.00 |
| Data Engineer | 440 | 21.000 |
| Manager | 129 | 6.00 |
| Machine Learning Engineer | 61 | 3.00 |
| Director | 17 | 1.00 |
 Figure 1 - Number of Jobs Against the Job Title
Figure 1 - Number of Jobs Against the Job Title
3.2 Minimum Education Level Required
I found that most jobs posting for data-driven jobs look for hires with Bachelors Degree. However, it should be noted that there is a sizeable numbers of employers looking for masters and PhD level of qualification.
An interesting observation was that 15% of employers did not specify university level of qualification either as they do not require a university qualification or have omitted the education level in the Job Description. This was a surprising result for me, but shows there are employers who might look past educational requirements
| Education Level | Frequency | Relative Frequency, % |
|---|---|---|
| Bachelors Degree | 1035 | 51.00 |
| PhD | 299 | 15.00 |
| No Education Specified | 299 | 15.00 |
| Masters | 232 | 11.00 |
 Figure 2 - Requirement Frequency Against the Education Level
Figure 2 - Requirement Frequency Against the Education Level
3.3 Technical Skills Requested for Jobs
As expected Python was the most requested skillset that employers wanted prospective hires to have it is closely followed by SQL. Big data platforms such as Apache Spark and Hadoop alongside Scala are relatively high in demand as well.
I was very surprised to see that R was not highly requested in the technology industry but I postulate that R is used more often in academic circles.
| Technical Skills | Frequency | Relative Frequency, % |
|---|---|---|
| Python | 1351 | 66.00 |
| SQL | 1193 | 58.00 |
| Excel | 763 | 37.00 |
| Spark | 629 | 31.00 |
| Hadoop | 531 | 26.00 |
| Scala | 509 | 25.00 |
| AWS | 328 | 16.00 |
| R | 159 | 8.00 |
 Figure 3 - Requirement Frequency Against the Technical Skills
Figure 3 - Requirement Frequency Against the Technical Skills
3.4 Academic Skills Requested for Jobs
Unsurprisingly, the top academic skill set looked for by employers is Machine Learning. However other academic skills sets such as DevOps, Statistics and Database Management was rarely mention, and Calculus was not mention at all.
I postulate that many employers expect these skills to be picked up during their university modules and would not be needed to be stated as a requirement.
 Figure 4 - Requirement Frequency Against the Academic Skills
Figure 4 - Requirement Frequency Against the Academic Skills
3.5 Hires by ownership type
We found that by ownership, the biggest hiring group of data driven jobs is the private sector, made up of privatised and public companies. It is not surprising that public companies are the biggest players since their profit-driven ethos would draw them to capitalise on new technology and skill sets that can help to streamline their operations and increase profits.
| Ownership | Number of Jobs | Relative Frequency, % |
|---|---|---|
| Company - Private | 815 | 40.00 |
| Company - Public | 503 | 25.00 |
| Government | 258 | 13.00 |
| Subsidiary or Business Segment | 33 | 2.00 |
| College / University | 16 | 1.00 |
| Contract | 9 | 0.00 |
| Unknown | 9 | 0.00 |
 Figure 5 - Tree Map Diagram of Ownership Type
Figure 5 - Tree Map Diagram of Ownership Type
3.6 Job Description Word Cloud
In the job description, we find that knowledge in machine learning is the most popular skill that is requested by employers.
Other notable skills are Data Mining, Predictive Modelling, Data Pipeline, Natural Language Processing(NLP) and big data.
 Figure 6 - Job Description Word Cloud
Figure 6 - Job Description Word Cloud
4. Conclusions
Overall, I’m satisfied with the outcome of this project. I was able to fulfil my 2 goals of the project which was to have a better understanding of the Data centric Job Market and hone my web scraping techniques.
However, I acknowledge the assumptions and limitations to the dataset and would like to minimised these in future iterations.
My future works include gathering data from Linkedin Jobs as well to increase the sample size of my search.
Thank you for viewing!(:
5. Acknowledgement
This project would not have been possible without the resources shared by other Github members. There are 2 notable Github members I would like to thank, they are Mr Ken Jee and Mr Ömer Sakarya.
6. Files in this Repository
The files in this bullet points are ordered in a chronological order of usage for this project.
- “chromedriver”: Needed for the webscraping algorithm in the 2nd bullet point
- “glassdoor_scraper.py” : The Glassdoor webscraping algorithm in Python
- “Part 1. Data Collection.ipynb” : The notebook where we call the webscraping algorithm for the different job titles
- “Part 2. Data Cleaning.ipynb” : The notebook with various cleaning algorithm after the data is collected
- “Part 3. Data Analysis.ipynb” :
- “Various Job Titles CSV Files” Folder : Folder containing the CSV files that we save after the Data Collection step in bullet 3
- “Various Graphical Visualisation” Folder : Folder containing the various Data Visualisation plots created during the Part 3. Data Analysis in .png format.
- “LICENSE” : MIT license for open source projects
- “README.md” : Documentation of the project
7. Disclaimer
This findings were collected in May 2020 and represents data accurate to that date that has been collected from Glassdoor. In no way, does past performances guarantee future results and employment. In addition, the data from one job site does not represent the entire job scene. I intended this post to give a sampled overview of the job market and should not be taken as a population representation.